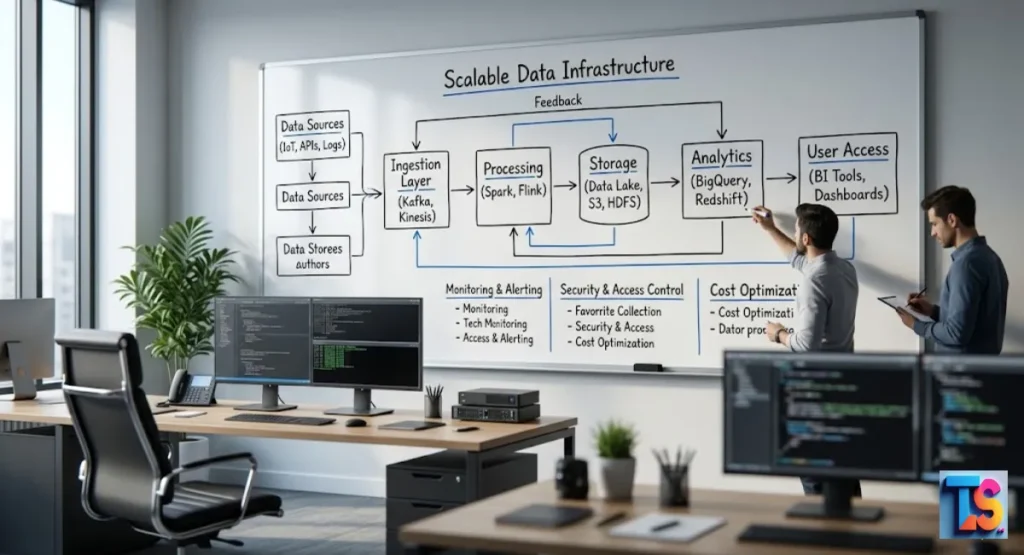
Mastering data scraping efficiency requires a move away from simple scripts toward robust, scalable architectures. If you treat massive crawls like small projects, you will face memory crashes, IP blocks, and corrupted data.
Professional teams now rely on distributed web crawling frameworks and smart filtering to handle millions of links safely. By implementing structured data collection and careful proxy management, you can harvest vast amounts of information while mimicking human behavior to avoid security triggers.
This guide details the Best Practices for Extracting Large URL Lists using essential frameworks and scaling tactics for modern data teams in 2026. Follow these professional automated web crawling strategies to gather clean, actionable insights at scale.
Why Mass URL Extraction Breaks Standard Scraping Workflows
Standard scripts fail at scale because they treat big data like small files, causing memory crashes and triggering automated defense systems. Transitioning to professional automated web crawling requires moving away from simple linear loops and adopting resilient, distributed infrastructure.
You must move to advanced data extraction strategies to keep systems running. Large crawls require smart management of your computer resources. Professional tools ensure that you handle millions of links without system failures or getting blocked by website security software.
The Infrastructure Limit: Memory Bloat vs. Disk Caching
You must store your URL list on a disk rather than in your computer’s short-term memory to prevent your program from crashing. Think of your computer RAM like a small desk; if you put a million papers on it, the desk will collapse, but if you keep them in a filing cabinet, you can handle any volume.
In my experience, using a Redis-backed queue to manage URL state saves 40% more system memory compared to storing URLs in local Python lists.
The “Anti-Bot” Wall: IP Burn Rates and Cloudflare Escalation
Websites use security layers to block traffic that looks repetitive or fake. Avoiding IP bans requires you to act like a normal user rather than a computer, as modern security tools flag connections that do not match standard browser patterns.
Using high-quality residential proxies is the standard for 2026. Data center IPs are flagged by almost every major security provider within seconds of heavy use.
Data Integrity: The Problem of “Infinite Trailing Slashes” and URL Parameters
You must clean and normalize your links before starting to prevent your scraper from getting stuck in endless loops. Imagine a website as a library where every aisle has a “sort by color” button; if you do not ignore the filter tags, you will visit the same shelf a thousand times, ruining your structured data collection.
Stage 1: Smart URL Discovery and Pre-Filtering (Before You Crawl)

Pre-filtering your list before sending a single request ensures you only visit pages that provide real value. This step drastically reduces unnecessary traffic and keeps your project costs low. This process allows you to find different methods to extract website links valid quickly while avoiding wasted requests. How to Extract URLs Effectively, always filter your data before you begin the actual scraping process.
Harnessing sitemap.xml and Robot Index Parsing
Checking the site map first is the fastest way to find every valid page without wasting resources. Think of the sitemap.xml like a store directory at the mall entrance; it tells you exactly where every shop is located, so you do not have to walk through every hallway to find them.
Early Deduplication: Using Bloom Filters and Redis Sets to Protect Proxy Credits
You should never waste money visiting a URL you have already seen by using a filtering tool to track your history. A Bloom Filter acts like a quick-check bouncer at a club door; it remembers everyone who has already walked in, so you never process the same link twice during your work.
URL Normalization: Standardizing Query Parameters for Cleaner Bulk Operations
Standardize your links to ensure that small changes in URL order do not create duplicate entries. Think of this as turning different versions of a product name into a single, uniform ID so your database stays clean and easy to search. Always strip UTM tracking parameters before adding URLs to your queue to avoid duplicates.
Stage 2: High-Performance Extraction Architecture

To handle large lists, your code must perform many tasks simultaneously rather than waiting for one page to finish. This server-side optimization is the difference between a project taking weeks versus taking hours. You need high-performance tools that manage hundreds of requests at once without slowing down your computer or your internet connection.
Synchronous vs. Asynchronous Methods
| Method | Speed | Resource Usage | Difficulty |
| Synchronous | Slow | High | Easy |
| Asynchronous | Fast | Low | Moderate |
You must use asynchronous processing to send multiple requests at once instead of waiting for each one to finish. Think of asynchronous processing like a waiter taking multiple food orders at once instead of standing at the kitchen window waiting for one plate to be cooked before taking another order from a different customer.
Setting Up Distributed Workers (FastAPI, Docker, and Kubernetes Clusters)
When your task grows too large for one computer, you should split the work across multiple machines using containers. Think of this as hiring a team of workers; if one worker gets tired or stuck, the others continue the job, ensuring the project never stops and your data collection continues without any interruption.
Stream Processing: Storing Raw HTML (Hot vs. Cold Database Storage)
Store raw data in a fast, temporary queue and move finished results to a cheaper, long-term location. Think of your hot storage as a busy kitchen counter where food is prepped, and your cold storage as the walk-in freezer where you keep inventory for later use. This keeps your active database fast and responsive.
Stage 3: Bypassing Advanced Rate Limits and Bot Defenses
You must blend in with real user traffic to keep your scraping project running smoothly without being blocked. Blending in involves mimicking human behavior down to the way your computer shakes hands with the server. Proper proxy management is essential to mask your identity and maintain a steady flow of data from the target website.
Intelligent Proxy Pools: Mapping Geolocation to Residential IPs
Always match the location of your proxy to the location of the website visitors to avoid raising suspicion. If you connect from a different country than the website main audience, the security system will see that as a red flag. Always choose proxies that look like real home internet connections for better results.
Beyond User-Agents: Spoofing TLS Fingerprints and Request Headers
Modern security tools look at your computer’s TLS fingerprint, which is like a unique digital handshake that reveals if you are a real browser or a script. Use advanced tools to match the handshake of a modern, popular web browser so you look like a normal visitor to the server.
Throttling with Exponential Backoff: Managing Your Error Budget
When a website tells you to slow down, you should wait longer and longer between each attempt to avoid being blacklisted. Think of this like a polite conversation; if someone asks you to stop talking, you wait a moment, then wait even longer if they look annoyed, showing you respect their limits.
Benchmarking the Best URL Extraction Tools [2026 Comparison]
You should choose the right how web scraping works tools based on the complexity of the website and the volume of data you need. Different frameworks provide different levels of control and speed. Always evaluate your specific needs, such as JavaScript rendering or proxy management, before you select a tool for your next large extraction project.
Battle-Tested Frameworks: Scrapy vs. Crawlee
Scrapy is the best choice for speed on simple pages, while Crawlee is better for modern, complex websites. If the site feels like a desktop app inside a browser, Crawlee is the right choice to handle the extra technical requirements and JavaScript-heavy elements found on many modern websites today.
Headless Automation: Playwright vs. Serverless Puppeteer Clusters
For sites that require you to click buttons or log in, Playwright is the best tool for the job. It behaves exactly like a real human using a mouse and keyboard, making it very difficult for websites to distinguish you from a real visitor. It is faster and more reliable than older tools.
Managed Extraction APIs: Offloading JS Rendering and Proxies
If you want to save time and effort, use an API that handles all the technical defense-bypassing for you. This allows you to focus on your data rather than fixing broken proxies or updating your bot-evasion tactics. These services are perfect for teams that need reliable data without managing complex server infrastructure.
The Legal and Ethical Compliance Checklist
You must always follow the rules set by the website to ensure your project stays safe and ethical. Is Web Scraping Legal 2026, respecting the website owner’s guidelines is a core part of professional data collection. When you follow these rules, you avoid legal issues and ensure your scraping tools maintain a good reputation across the web.
How to Read and Honor Aggressive robots.txt Directives
Always check the robots.txt file first to see which parts of the site you are allowed to visit. This is the website owner’s way of setting boundaries, and following them is the best way to maintain a positive relationship with the site and avoid being blocked by their security team.
Scraping Public vs. Authenticated/Private Data Spaces
Only scrape data that is available to everyone on the open web. Accessing private data or data behind a login wall is a common way to trigger legal trouble, so keep your scope limited to public information. This keeps your data extraction strategies clean and prevents you from breaking any privacy rules.
Off-Peak Extraction Strategy: Minimizing Burden on Target Infrastructure
Schedule your biggest scraping tasks during the website’s nighttime hours when they have less traffic. Being a good citizen of the internet by not overwhelming their servers will keep your connection stable and help you avoid being blocked. Always aim to minimize the burden you place on the target server.
Summary
To ensure your project is successful and scalable, keep this checklist handy:
Move to Disk: Never keep large URL lists in RAM to prevent crashes.
Use Async: Parallelize requests to maximize speed.
Normalize Early: Clean URLs before crawling to avoid redundant work.
Match Identity: Use residential proxies and modern TLS settings to look human.
Respect Rules: Always check robots.txt and scrape only during off-peak hours.
Prioritize Public Data: Avoid private or password-protected areas to stay compliant.